

Data Analytics su dati clinici
Il Progetto
L’analisi dei dati clinici relativi alla salute di un singolo soggetto o di una popolazione di soggetti al fine di individuare fattori di rischio, effettuare diagnosi precoce o anticipare la prognosi, è uno dei problemi più critici della medicina moderna. Le tecniche di Data Mining (DM) e più in particolare le tecniche di Machine Learning (ML) hanno ottenuto un grande interesse in medicina per la possibilità di analizzare grandi quantità di dati per ottenere informazioni per migliorare l’approccio diagnostico e terapeutico. L’uso di queste tecniche in ambito medico sta cambiando il modo di approcciarsi ai pazienti, perché potrebbero semplificare e velocizzare i processi clinici.
Il progetto è stato sviluppato nell’ambito del contratto Analitiche per la gestione della Cartella Clinica Riabilitativa Integrata Elettronica, stipulato tra ACTOR s.r.l. e TSC Global Consulting s.r.l.
Si è realizzato un algoritmo che, facendo uso di tecniche di Machine Learning, consenta una classificazione dei pazienti finalizzata alla più opportuna terapia riabilitativa. I dati disponibili di cui è stata effettuata una dettagliata analisi statistica sono contenuti nel RAPPORTO ACCETTAZIONE/DIMISSIONE (RAD) Area Riabilitativa (DGR 731/2005), in cui è riportato lo stato clinico del paziente alla data di accettazione e di dimissione, utilizzando l’indice di Barthel (BI) come misura delle attività di vita quotidiana del paziente. In particolare, si è sviluppato un modello predittivo che produce come outputs la classe di BI (alto, basso, incerto) e il valore di BI predetto e Standard Deviation (SD) come di norma viene effettuato in ambito di stime per confidenza, e forniscono un range all’interno del quale si ritiene molto probabile che cada il valore effettivo del BI. Sulla base della patologia che ha indotto il ricovero, si è reso necessario suddividere i pazienti nei due gruppi ortopedici e neurologici che presentano caratteristiche molto diverse tra loro riguardo la risposta alla terapia riabilitativa e realizzare due modelli previsionali distinti per le due categorie di pazienti.
L’algoritmo di ML si basa su un approccio a due livelli. Nel primo livello si è realizzato un classificatore per definire la classe di appartenenza del pazienti in relazione al valore di uscita del BI sopra/sotto una soglia. Il classificatore restituisce per ogni paziente un valore tra 0 ed 1. Valori superiori/inferiori rispettivamente ad opportuni valori soglia classificano il paziente come BI alto o BI basso. Diversamente il paziente viene classificato con BI incerto. Dopo essere stato classificato in alto, basso oppure incerto, al secondo livello ogni paziente viene preso come input da 3 modelli di regressione di ML che forniscono una predizione puntuale del BI in output. Per ogni tipo di paziente (ortopedici, neurologici) e per ogni tipo di classificazione al primo livello (alti, bassi, incerti) sono stati addestrati 3 modelli diversi per un totale di 18 modelli.
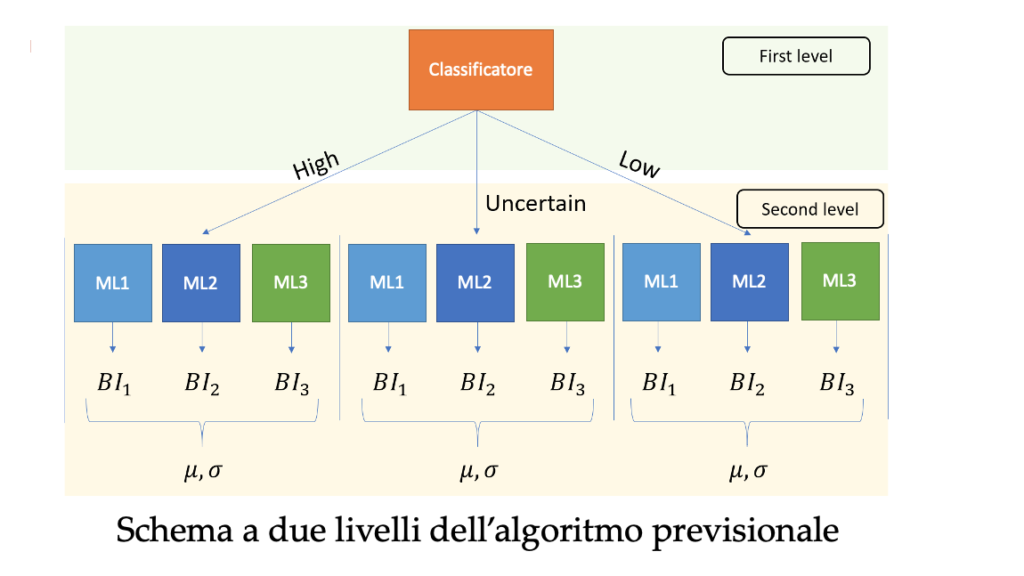
Il valore di BI predetto è pari alla media dei valori restituiti dai 3 modelli e la deviazione standard delle 3 predizioni indica quanto i tre modelli concordano sulla predizione restituita. Applicando questo modello, una stima dell’errore medio è pari a 9.077, ossia sulle previsioni restituite in media sbagliamo la previsione del BI di 9 punti (su una scala 0-100). Nello specifico, l’errore medio ottenuto risulta pari a 7.65 e a 10.73 rispettivamente per i pazienti di tipo ortopedico e neurologico.