

Previsioni statistiche in contesti complessi: vendite in presenza di promozioni nella GDO
Utilizzo di SVM, RBF, ANN
Il progetto
Il problema della previsione delle vendite di un un dato bene di consumo è sempre stato di fondamentale interesse per la Grande Distribuzione Organizzat (GDO). Infatti sulle previsioni delle vendite si basano le politiche di riordino delle scorte e le associate politiche di gestione finanziaria degli acquisti.
In passato i principali metodi utilizzati per la previsione delle vendite sono stati metodi statistici basati su modelli autoregressivi delle serie storiche dei dati disponibili, come il metodo ARIMA , il metodo di Box e Jenkin, e il metodo dello smoothing esponenziale di Winter.
A partire dagli anni 90 sono stati introdotti metodi più sofisticati, in cui la previsione è effettuata non solo utilizzando la serie storica del dato da prevedere, ma anche altre serie storiche che possono concorrere a determinarne l’evoluzione. Tali metodi rientrano nella classe del Machine Learning, e hanno in comune il fatto che danno luogo a un modello algoritmico di tipo input-output in cui l’output e’ il valore predetto del dato, l’input i valori di una lista di cosiddetti attributi rilevanti per la predizione.
Più in particolare i modelli di Machine Learning utilizzati sono quelli delle Artificial Neural Network (ANN), delle Radial Basis Functions (RBF) e delle Support Vector Machines (SVM). In ogni caso lo sviluppo del modello richiede una fase di addestramento e di validazione che si effettua utilizzando dati storici, e che consiste nel tuning di parametri caratteristici del modello. Quello del tuning è un problema di ottimizzazione matematica per cui sono stati sviluppati sofisticati algoritmi che tengono conto della loro particolare struttura.
Ovviamente le previsioni risultano tanto più accurate quanto più la serie storica dei dati e’ regolare, cioè si presenta con un andamento che si ripropone simile nel tempo. Nel nostro caso ci è stato chiesto invece di verificare l’ettendibilità di previsioni effettuate in contesti di alta irregolarità, determinata da una campagna di promozione per la vendita di un bene di consumo. In presenza di promozione la quantità da offrire va misurata con grande attenzione: se risulta eccessiva si può verificare un fondo di magazzino, dannoso soprattutto per i beni deperibili, mentre se risulta insufficiente si può verificare un out of stock, con il risultato che il cliente si rivolga altrove facendo venir meno il rapporto di fidelizzazione con il punto vendita.
Nel nostro caso, proposto da una importante catena della GDO, il bene di consumo considerato è un particolare tipo di pasta. I dati di vendita provengono da due punti vendita, caratterizzati da differenti volumi di pasta venduta. I dati disponibili coprono cinque anni, quelli di quattro anni sono stati utilizzati per l’addestramento e la validazione della Learning Machine, e la previsione è stata effettuata sui dati del quinto. Come attributi di input sono stati utilizzati dati di calendario: mese, giorno del mese, e giorno della settimana: è infatti probabile che di sabato si venda più che di lunedì, e nell’ultima settimana del mese, mese di paga, più che nella penultima. Inoltre sono stati utilizzati quattro attributi specifici per il problema in esame: un attributo booleano che vale 1 se in quel giorno è attiva una promozione, 0 altrimenti, il numero di ore di apertura del punto vendita in quel giorno, il prezzo di vendita di quel tipo di pasta in quel giorno, e per finire il numero totale di scontrini di cassa in quel giorno, significativi per valutare quanti clienti sono entrati nel punto vendita. Per quel che riguarda quest’ultimo attibuto nel quinto anno, non potendolo considerare noto, è stato a sua volta oggetto di previsione mediante una SVM.
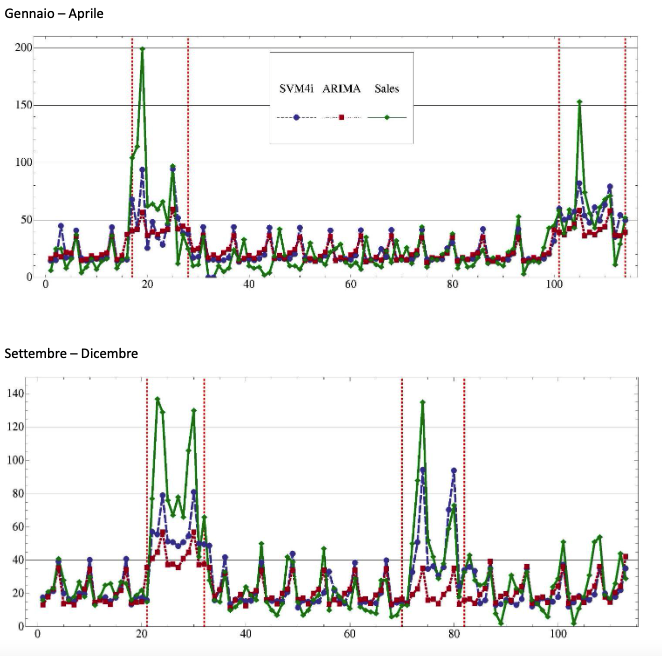
Per la previsione di vendita della pasta sono state sperimentati tutti i tre metodi di Machine Learning citati all’inizio, e i risultati sono stati confrontati con quelli ottenuti con i tre metodi statistici tradizionali. Dal confronto è risultato vincente il metodo basato sulla SVM, che quindi ha fornito il risultato finale.
Nelle figure le previsioni nei periodi Gennaio – Aprile e Settembre – Dicembre con evidenziati i periodi di promozione.
Riferimenti
An application of Machine Learning to sales forecasting under promotions
An application of support vector machines to sales forecasting under promotions